

DataChain - Solution Data de bout-en-bout
Description
Solution souveraine « End to End » Data/IA de captures, d'analyses, d'industrialisation et d'exposition de la donnée- Types d'utilisateurs Professionnel, Particulier
- Langue de l'interface utilisateur Français, Anglais
- Version 7.5








Une question sur cette solution ? envie d'une démo ? besoin d'un devis ?... Contactez-nous.
Détails
DataChain est une solution de Data Virtualisation, Data Transversale, souveraine, de gouvernance, gestion et analyses de la chaîne de valeurs Data. C'est une solution qui s’adresse à tous les profils d’une organisation (Multi-persona), rapide à configurer et à itérer, réduisant les dépendances, et laissant la liberté de se concentrer sur les besoins métier de manière simple et accessible.
La solution DataChain permet de déplacer le centre d’intérêt des organisations vers leurs données et la valeur que ces dernières vont générer. Permettre aux utilisateurs de tirer avantage des Data devient alors indissociable des actions de collecte, préparation, qualification, analyse, visualisation et présentation des données.
L’objectif, envisager la donnée de manière descriptive, prédictive mais aussi prescriptive, croiser des données internes et externes aux entreprises, casser les silos, encourager les collaborations, apporter une vision transversale, le partage au-delà de l’échange, découvrir des tendances.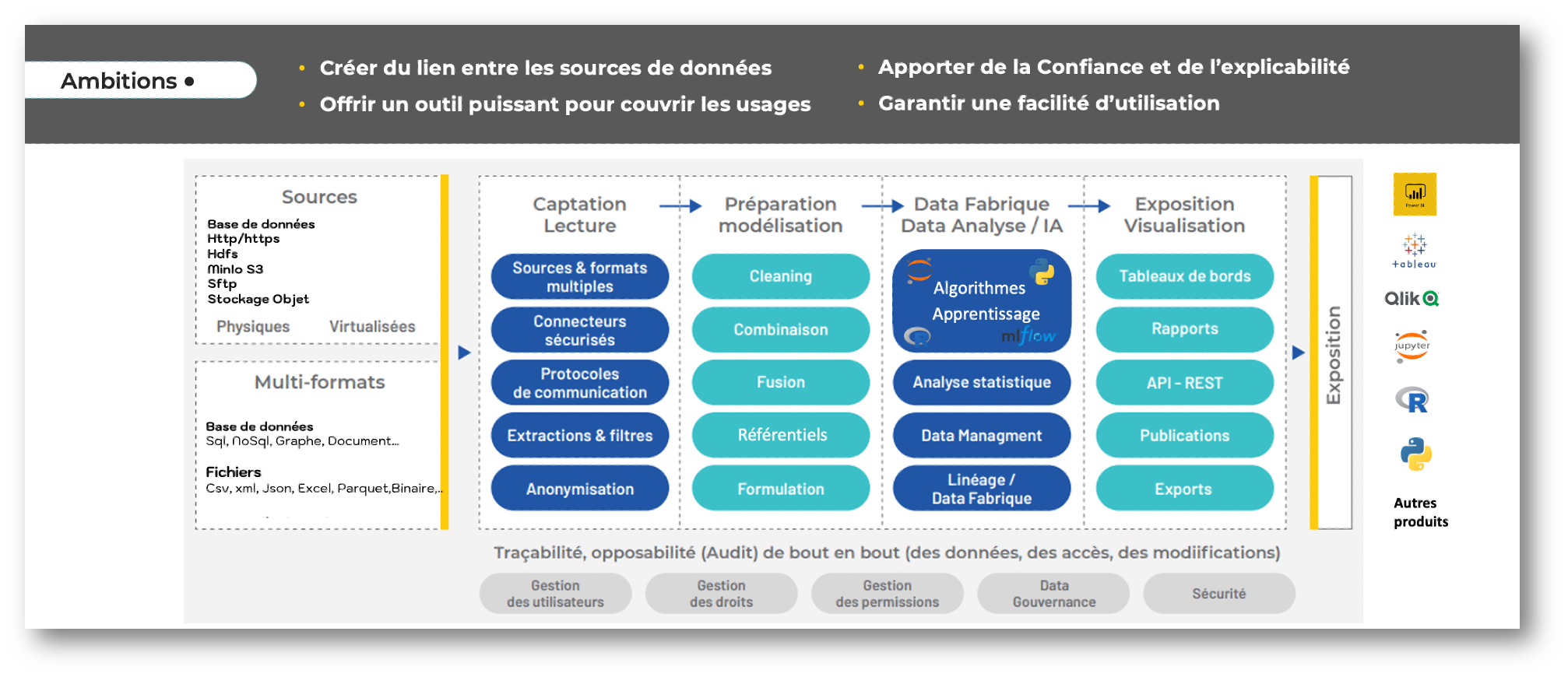
Fonctionnement
DataChain peut être est une boite à outils à destination de tous pour capter, manager, modéliser, analyser, relier, exploiter, exposer et comprendre les données, dans des environnements souverains, sécurisés, tracés et opposables.
La mission, fournir aux utilisateurs de DataChain des prestations de qualité et sécurisées afin de les accompagner dans leur transformation digitale, induite par l'essor du numérique.
L’efficience globale de la solution DataChain, l'innovation et l’approche agile d’Adobis Group sont les facteurs clés du choix de nos clients, pour assister les utilisateurs dans la conduite de leurs projets Data et l'élaboration de solutions créatrices de valeur.
DataChain va permettre de réconcilier tout ou partie des Data, quel qu’en soit la source, en mode direct (live) et/ou en mode statique avec ou sans stockage physique des données.
La mise en œuvre de DataChain va faciliter le management de l’ensemble des données, assurer un niveau de qualité exploitable, une traçabilité opposable, une sécurité aussi performante qu’importante, ce, plus particulièrement, concernant les données sensibles.
DataChain apporte la capacité de réaliser des traitements et d’intégrer de nouvelles valeurs via des pipelines de tâches en vue d’être exposés aux différents services pouvant les consommer en fonction de leurs propres besoins métiers contextualisés.
À qui s’adresse la solution
La solution s'adresse aux secteurs de la santé, des collectivités, de l'industrie et de la finance (de la petite entreprise au grand compte)
Points forts de la solution
* Plateforme Multi-projets / Multi-instances
* Plateforme Data End-to-End
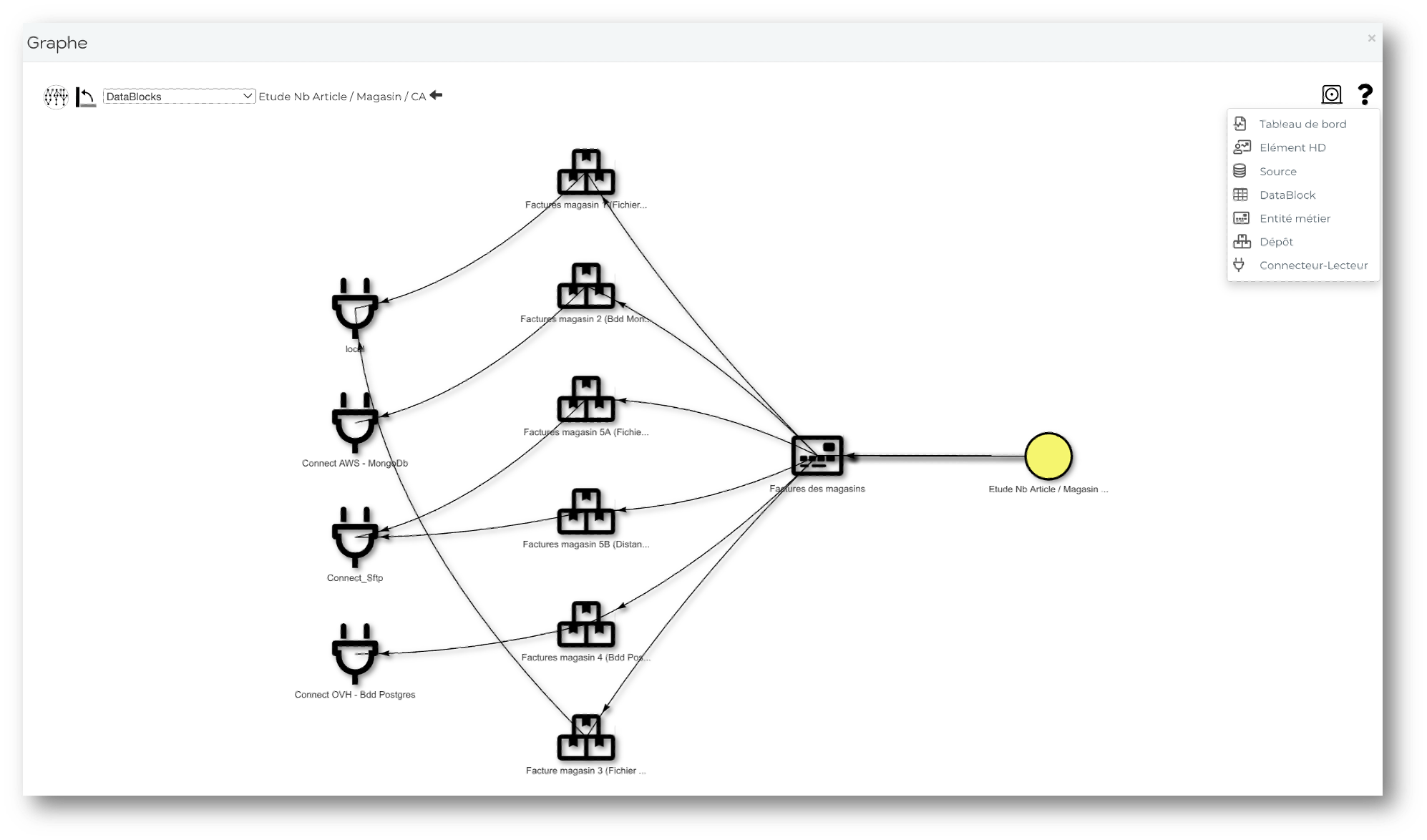
* Mode virtualisé et/ou Mode par extraction (Static)
* Multi-mapping - Multi-protocoles (S3, MinIo, Hdsf, Sftp, Bdd SQL, Nosql, Graph, ElasticSearch,....) - Multi-reader (Csv, txt, Excel, Parquet, Json, Xml, Binaire, Sql, Cypher, Collection Mongo,...)
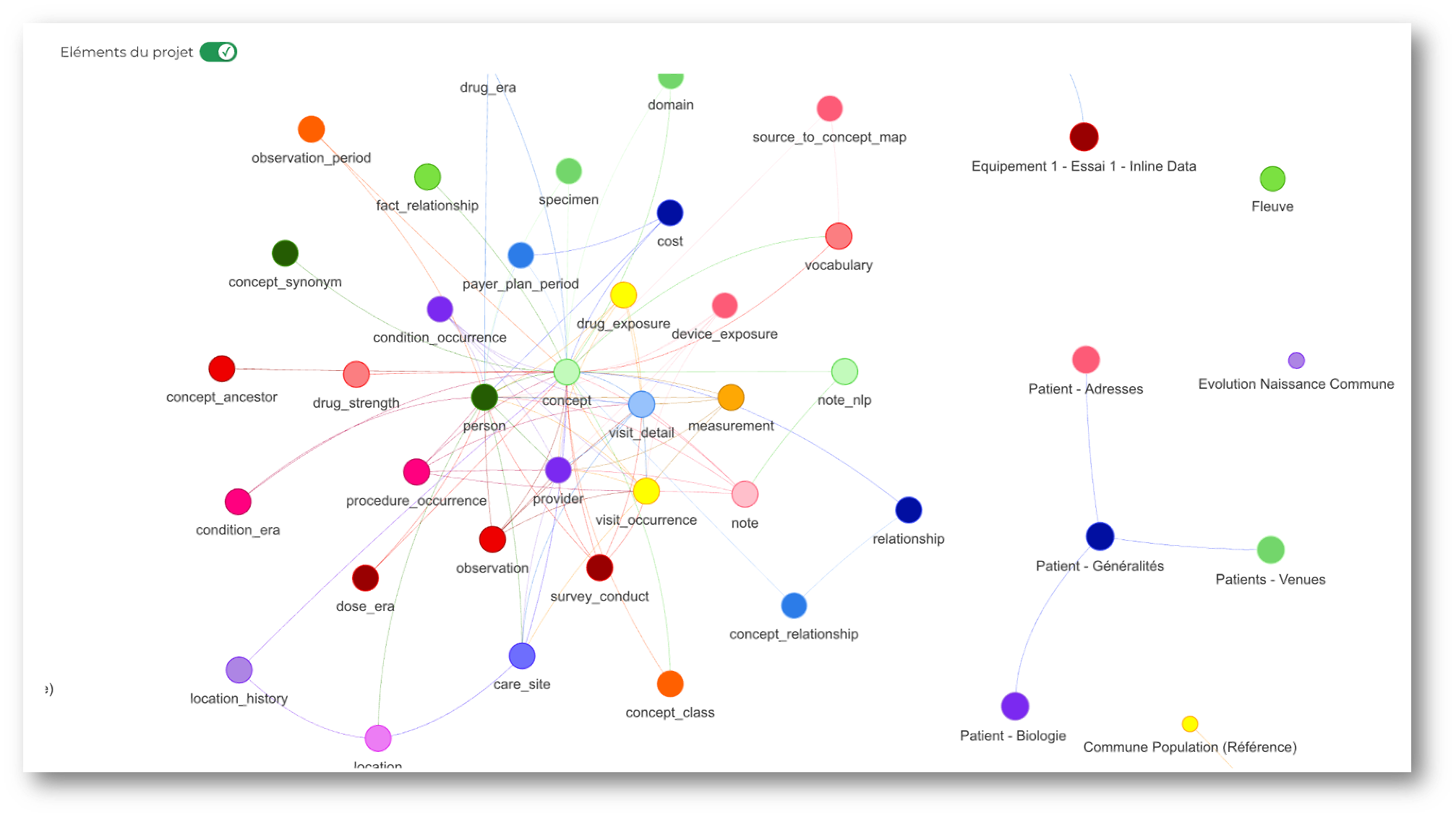
* Génération de modèle de données non déterministe Multi-sources
* Gestion des droits fins sur structure de données et données
* Gestion par utilisateurs et groupes d'utilisateurs
* Utilisabilité forte et niveau d'absatraction permettant une indépendance des traitements multi-protocoles
* Génération de pipeline et de workflow de traitement (fonction , jointure, union, gestionnaire de formules, filtre avancé, agrégations simples, multi-dimensionelles, pivots, opérations sur colonnes (timeséries, window, glissements,...), Stack, Explode, redimension, Tris,...)
* Statistiques dynamiques
* Environnement JupyterHub intégré avec Notebook DataScience (Python et R) sécurisé
* Gestion multi-environnements des notebooks
* Connection à dépôts GIT
* Intégration Mlflow
* Gouvernance native
* Gestion du cache et des persistances
* Moteur de calcul BigData en cluster et scalable (Spark)
* Traçabilité (Piste d'audit, Dossier de preuve, explicabilité...)
* Industrialisation et automatisation des processus (basé sur Airflow)
* Génération d'API REST dynamique sur DataSet avec documentation et consommation par Token
* Génération de visuels (Graphes multiples, Média, Tableaux, TimeLine, Cartographie)
* Génération et plublication de tableaux de bord
Cas d'usage
Santé – Centre Hospitalier :
- Capture et Réconciliation Multi-Silos
- Cartographie Patient – Zone d’attractivité
- Croisement base décès (OpenData) et base patient – Optimisation de l’archivage des dossiers
- Identitovigilance
- Indicateurs Ovalide
- Étude et optimisation du parcours patient dans un service d’urgence
- Analyse de données sur plateforme HDS (Hébergement Données de Santé)
Data Plateforme / Data Virtualisation d’une collectivité territoriale :
- 4500 sources de données
- Capture – Modélisation - Réconciliation – Multi-Maping – Pipeline
- Exposition API Rest et Dashboarding
- Transformation de blocs de données
- Expositions sécurisées et tracées vers les services métiers
- Collaboration des métiers
Finance – Une maison mère et ses filiales :
- Capture et réconciliation fichiers d’écriture comptable de volume important multi-sources, multiformats, consolidation des filiales
- Contrôle qualité suivant les règles établies
- Création et maintenance de référentiels / bonnes pratiques
- Tableaux de bord / analyse en temps réel / rationalisation et optimisation des décisions
Pas encore d’avis utilisateurs sur ce produit
Laisser un avisVous devez être connecté pour donner votre avis
